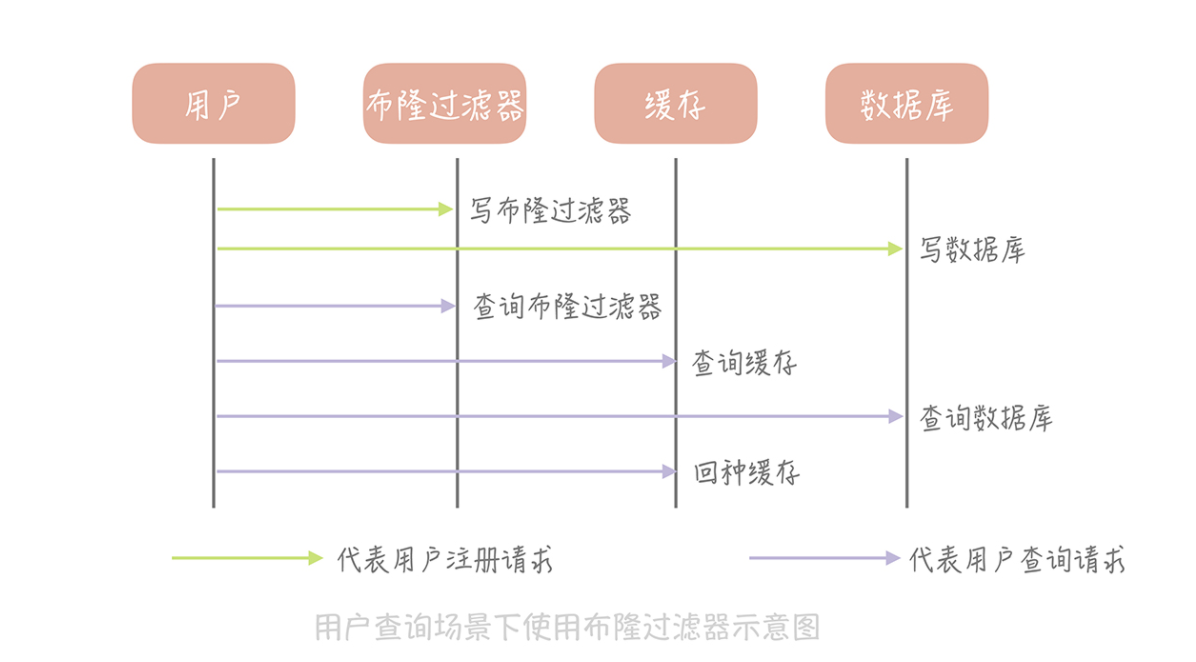
布隆过滤器
布隆过滤器(bloom filter)
布隆过滤器本质上是一种概率型的数据结构,用于检索一个元素是否在集合中,它将告诉你一个数据“一定不存在或可能存在。
理
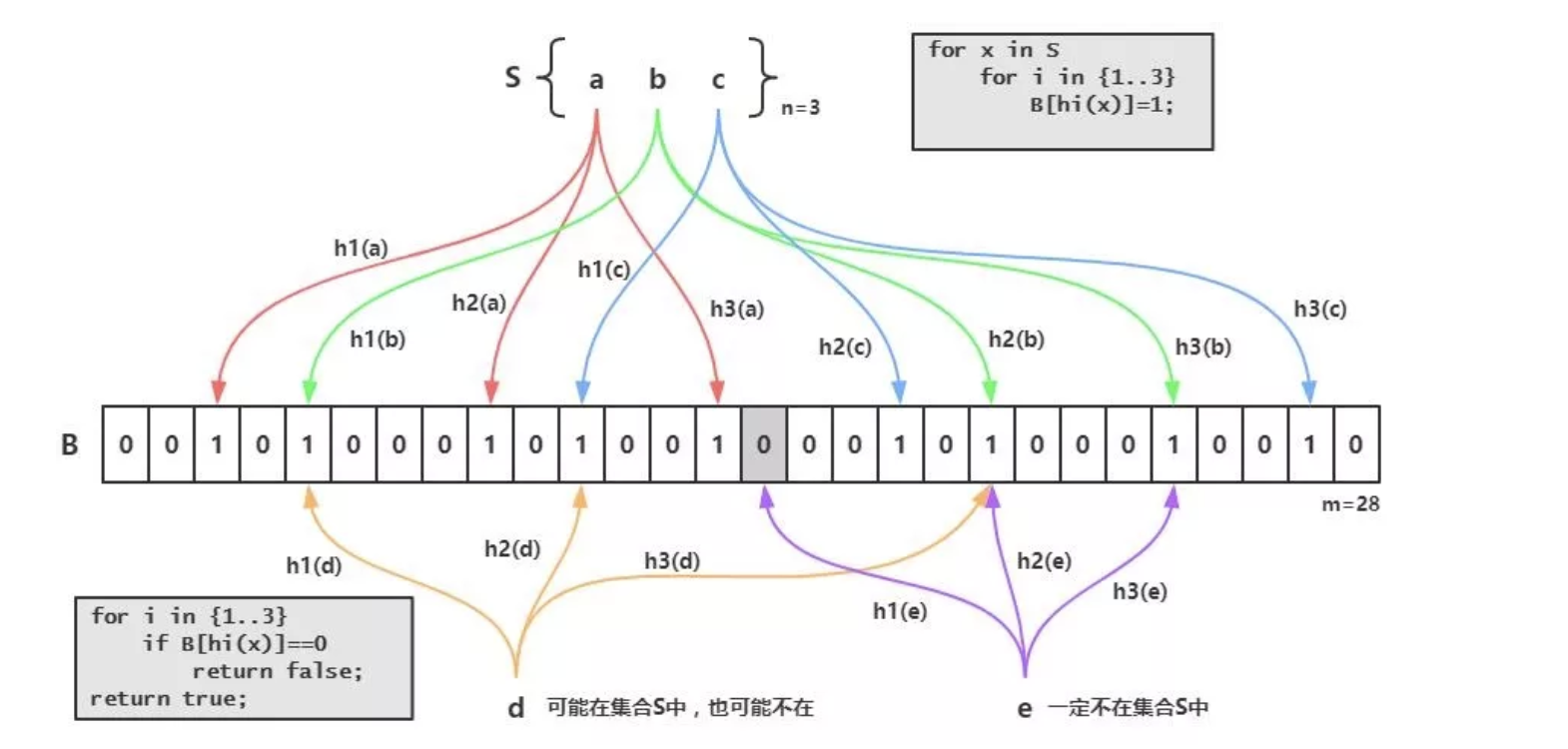
布隆过滤器由一个很长的二进制向量(位向量、位数组、Bit Array)和一系列的随机映射函数组成。
我们把集合中的每一个值按照提供的 Hash 算法算出对应的 Hash 值,然后将 Hash 值对数组长度取模后得到需要计入数组的索引值,并且将数组这个位置的值从 0 改成 1。在判断一个元素是否存在于这个集合中时,你只需要将这个元素按照相同的算法计算出索引值,如果这个位置的值为 1 就认为这个元素在集合中,否则则认为不在集合中。
针对hash冲突的问题,使用多个hash函数
优缺点
优点: 高效,存储空间占用小
缺点: 返回的结果是概率性的,而不是准确的 - 一定不存在,可能存在;不支持删除
应用场景
利用布隆过滤器减少磁盘 IO 或者网络请求,因为一旦一个值必定不存在的话,我们可以不用进行后续昂贵的查询请求。
布隆过滤器只会出现“false positive”的情况,因此如果布隆过滤器判断元素不存在,那么一定不存在,因此适用于缓存穿透(缓存穿透其实是指从缓存中没有查到数据,而不得不从后端系统(比如数据库)中查询的情况)
例: