mysql系列之基础
Mysql系列之基础
MySQL 基础
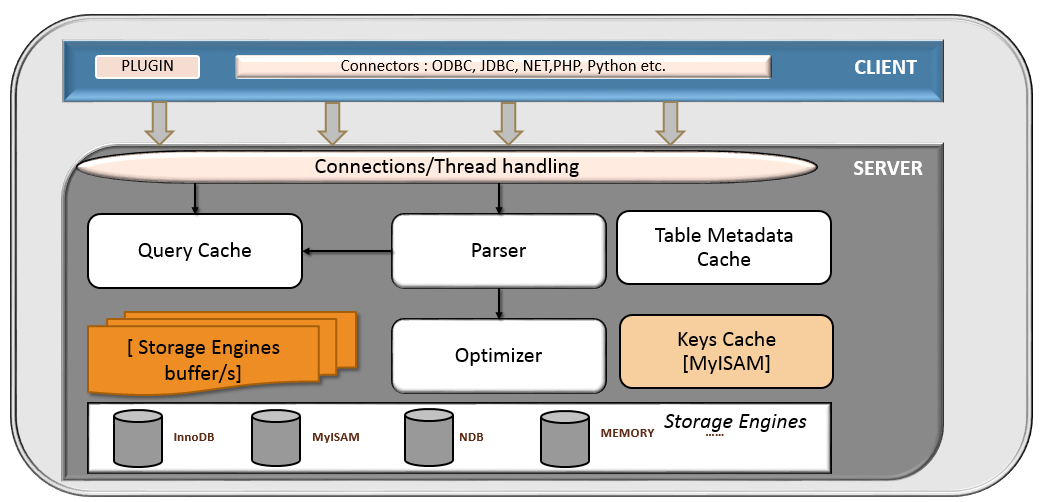
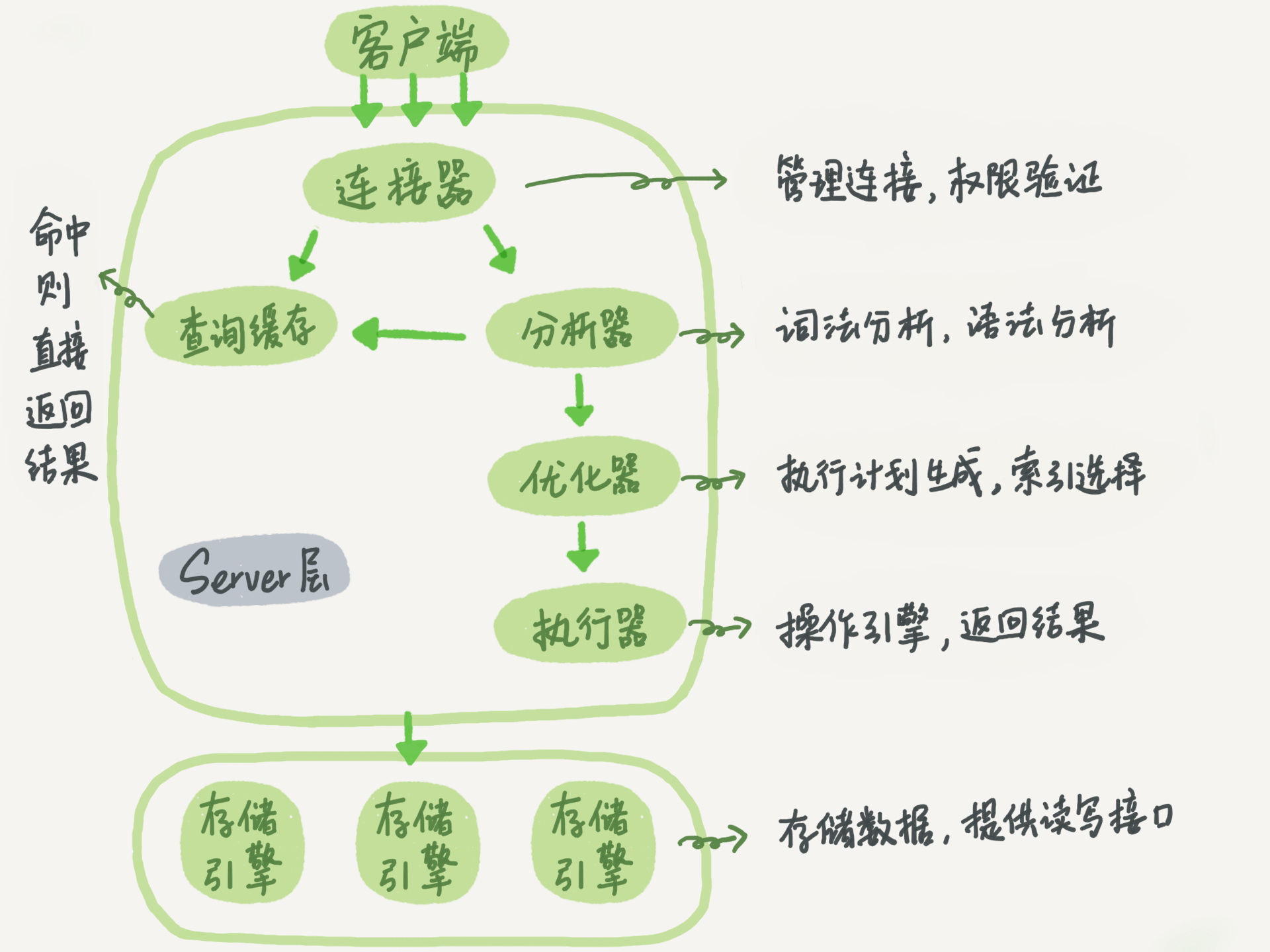
mysql 包括 server 层 和 存储引擎层,
server层
包括连接器,查询缓存,分析器,优化器,执行器,涵盖mysql 大多数的核心服务功能,所有跨存储引擎的功能都在这一层。
连接器
mysql -h\(ip -P\)port -u$user -p, 接受连接 + 身份认证
查询缓存
连接完成后,查询缓存,如果不在查询缓存中,执行后续步骤
利大于弊(实效、对于更新频繁命中率低), 8.0 删除了查询缓存。
分析器
语法分析,判断是否满足mysql语法。
优化器
在表中有多个索引是,决定使用哪个索引;多表关联,决定表的连接顺序。
执行器
执行语句
存储引擎层
储引擎层负责数据的存储和提取,常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。
存储引擎基于表而不是数据库,插件的形式。
MyISAM
不支持事务,表锁设计,支持全文索引,适用于OLAP
InnoDB
InnoDB存储引擎支持事务,主要面向OLTP(在线事务处理),特点
- 行锁
- 支持外键
另外多版本并发(MVCC)获得高并发,实现4种隔离级别,提供插入缓冲,二次写,自适应哈希,预读等
对于表中数据存储,采用聚集(cluster)的方式,表中数据按照主键顺序存放
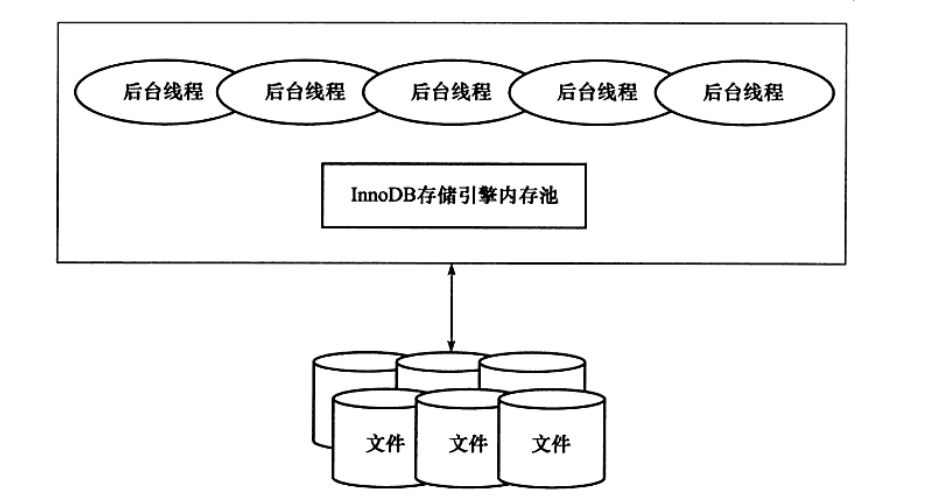
后台线程主要负责刷新内存池中的数据,保证缓冲池中的内存缓存是最近的数据,此外将已修改的数据文件刷新到磁盘文件保证数据库发生异常时
缓冲池
cpu与硬盘之间的速度差异 - 缓冲池, 即一块内存区域
- 读取: 先把从磁盘读到的页放入缓冲池,下次读相同页时直接从内存中读取
- 修改: 先修改缓冲池的页,再以一定频率刷新到磁盘, checkpoint 机制
缓冲池大小直接影响数据库整体性能,通过innodb_buffer_poll_size设置
缓冲池中缓存的数据页类型:
- 索引页
- 数据页
- undo页
- 插入缓冲 insert buffer
- 自适应哈希索引
- 锁信息
- 数据字典
其中数据页和索引页占了缓冲池一大大部分
LRU (非朴素LRU,防止热点数据刷出内存)
脏页: 缓冲池和磁盘不一致的页
重做日志缓冲(redo log buffer)
innoDB内存区除了缓冲池,还有重做日志缓冲,重做日志先放入该缓冲区,然后以一定评率刷新到重做日志文件。
刷新时机:
- master thread每一秒将重做日志缓冲刷新到重做日志文件
- 事务提交时会将重做日志缓冲刷新到重做日志文件
- 当重做日志缓冲剩余空间小于1/2,重做日志刷新到重做日志文件
checkpoint 技术
缓冲池刷新。
如果每当一个页发生变化(如DML,update,delete改变页内容-脏页,缓冲池中页版本要比磁盘新),就立即将新页版本刷新到磁盘,开销巨大,另外刷新磁盘如果发生宕机,那么数据就无法恢复。
为避免数据丢失,当前事务数据库普遍采用WAL(write ahead log)策略,当事务提交时,先写重写日志,再修改页。当宕机时,通过重做日志恢复数据(ACID中的Durability)
但是入股重做日志特别大那么恢复时间会很长,因此checkpoint解决一下问题:
- 缩短数据库恢复时间
- 缓冲池不够用(LRU溢出最近最少使用的页),脏页刷新到磁盘
- 重做日志不可用,刷新到磁盘
数据库宕机恢复,不需要重做所有日志,因为checkpoint前测得页都已经刷新回磁盘。
关键特性
1. 插入缓存
- 索引是辅助索引(secondary index)
- 索引不是唯一的
对于非聚集索引的插入和更新,不是一次性插入到索引页,而是先判断插入的非聚集索引页是否在缓冲池中,如果在就直接插入,如果不在则先放到insert buffer中,再以一定频率和辅助索引页子节点merge
2. 两次写
doublewrite- 数据页的可靠性: 当数据库宕机时有可能存储引擎正在写某个页,页只写了一部分,部分写失效
对缓冲池脏页刷新时,不直接写磁盘,先复制到内存的doublewrite buffer,之后分两次写入共享表空间的物理磁盘,然后同步磁盘。
如果页写入磁盘发生崩溃,恢复过程中可先重共享表空间的doublewrite找到页的副本,将其复制到表空间,再应用重做日志。
3. 自适应哈希
如果监控到建立哈希索引可带来速度提升,则建立哈希索引。
4. 异步IO
为提高磁盘操作性能,使用AIO : 区别于同步IO可以在发出io请求后,继续发送IO请求,全部IO请求发送完毕,等待所以IO处理完成。
5. 刷新邻接页
刷新一个脏页时,检测该页所在区的所有页,这样AIO可以将多个IO合并为一个
MySQL 文件
- 参数文件: 配置
- 【重要】日志文件: 错误日志、二进制日志、慢查询日志、查询日志等
- socket文件
- pid文件
- 表结构文件
- 存储引擎文件,真正存储了记录和索引等数据
参数文件
K-V, ,静态(整个实例周期)Vs 动态(可在运行时更新)
日志文件
- 错误日志
- 二进制日志(binlog)
- 慢查询日志(slow query log)
- 查询日志
慢查询日志
- long_query_time 阈值
- log_queries_not_using_index,记录sql日志,如果该查询没有使用索引
查询日志
记录所有对MySQL数据库请求的信息
二进制日志
二进制日志(binary log)记录了对数据看执行更改的所有操作。
主要作用:
- 恢复(recovery),point in time 恢复
- 复制(replication), master-slave replication
- 审计(audit)
binlog format: row 、statement(更小)
表结构定义文件
frm后缀,存放表和视图。
InnoDB存储引擎文件
表空间文件
innoDB 按表空间存储数据。
重做日志文件 (InnoDB 存储引擎针对事务)
区别于binlog:
- 二进制日志文件是所有引擎通用的日志,而重做日志只是有关innoDB 事务相关的日志。
- bin log是在事务提交时一次性写入的,redo log 是事务过程中不断写入的。
- bin log 无论是row 还是statement,属于逻辑日志;redo log是关于每个页的更改物理情况。

另外redolog 不是直接写磁盘,先写入redo log buffer,然后按照一定频率刷新到磁盘。
后台线程- 主线程, 不管事务是不是提交,每秒固定刷新
参数
innodb_flush_log_at_trx_commit表示在事务提交时,处理重做日志的方式有效值: 0、1、2. 0表示不刷新,等待主线程刷新。1是同步,2是异步。 - 设置为1,保证
InnoDB 表
逻辑存储结构
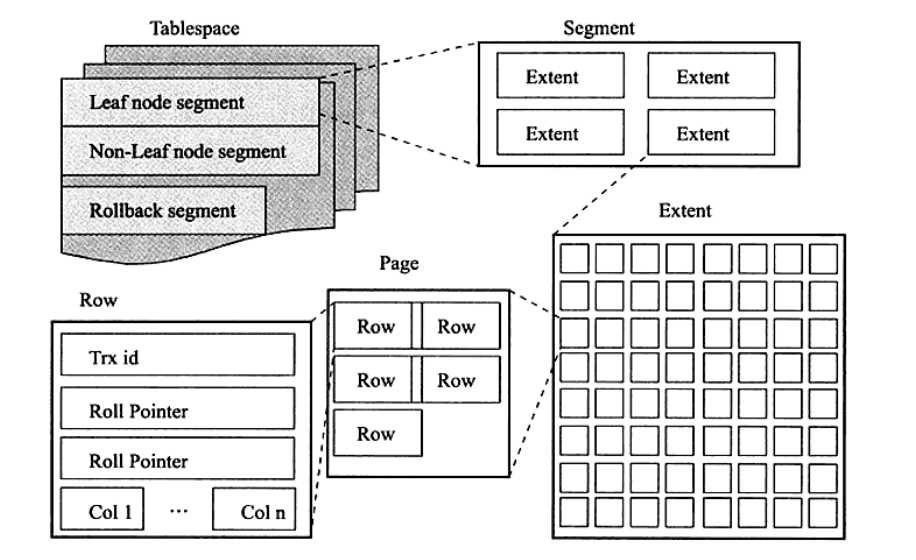
索引组织表
InnoDB中,表是根据主键顺序组织存放 - 索引组织表
每张表都有主键,如果没有显式定义主键
- 首先判断是否有unique not null, 有的话作为主键
- 不符合上述条件,创建rowid
约束
保证数据完整性, innodb提供如下约束:
- Primary Key
- Unique Key
- Foreign Key
- Default
- Not Null
通过表建立时或者alter table命令。
外键约束
被引用的表称为父表,引用的表称为子表。
外键定义时可指定ON DELETE和ON UPDATE,即对父表进行update或delete时,对字表做的操作
- CASCADE
- SET NULL
- NO ACTION
- RESTRICT (默认)
视图
View的作用:
提供抽象,针对一些引用程序,本身不关注基表,只需按照视图定义读取或更新数据。
分区
分区并非在存储引擎完成,5.1版本添加了对分区的支持。
分区是将一个表或索引分解为多个更小部分。
水平分区: 同一表中不同行记录分配到不同物理文件
垂直分区:同一表中不同列记录分配到不同物理文件 (mysql 不支持垂直分区)
分区分为
- 局部分区索引: 分区中既存放数据又存放索引
- 全局分区索引: 数据分区,索引不分区。 (mysql不支持全局分区索引)
分区
- range
- List
- Hash 自定义
- Key分区, mysql 提供的哈希函数进行分区
Range分区

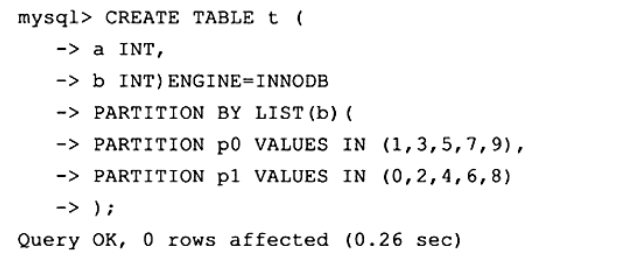
List 分区
Hash分区

用户只需指定分区列(值或者表达式),分区数量。
Key分区
类似于Hash分区,Key分区使用MYSQL提供的函数进行分区。
分区与性能
针对OLTP(在线事务处理),如blog,电子商务,网络游戏等。 分区不一定会提高性能。
例如: 1000万行的数据,针对主键hash分10个区, 每个分区100万行数据。但100万和1000万B+树高度区别不大,主键分区并没有大的提升,如果按照别的key 查询反而需要扫描所有分区性能下降。
TODO:
TO be continue...