学习笔记之其他树
[学习笔记] - LSM, Trie树
LSM
Log-Structured Merge-Tree (NoSQL)
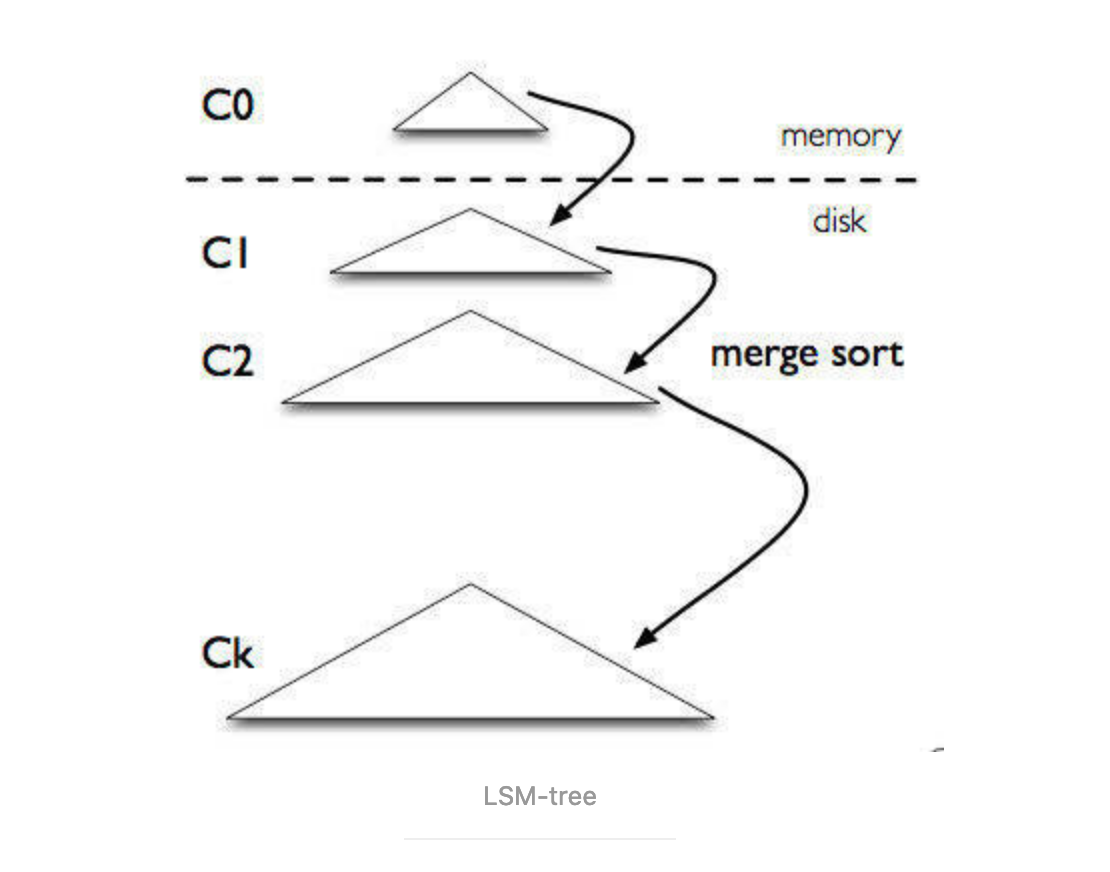
LSM树和B+树的差异主要在于读性能和写性能进行权衡,在牺牲的同时寻找其余补救方案。
B+树存储引擎,不仅支持单条记录的增、删、读、改操作,还支持顺序扫描(B+树的叶子节点之间的指针),对应的存储系统就是关系数据库。但随着写入操作增多,为了维护B+树结构,节点分裂,读磁盘的随机读写概率会变大,性能会逐渐减弱。LSM树(Log-Structured MergeTree)存储引擎和B+树存储引擎一样,同样支持增、删、读、改、顺序扫描操作。而且通过批量存储技术规避磁盘随机写入问题。当然凡事有利有弊,LSM树和B+树相比,LSM树牺牲了部分读性能,用来大幅提高写性能。
Trie树
Trie树,即字典树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较。
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
前缀树的3个基本性质:
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符。
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
- 每个节点的所有子节点包含的字符都不相同。
例子: 搜索引擎搜索提示, 有 6 个字符串,它们分别是:how,hi,her,hello,so,see,查找某个字符串是否存在。
构造过程:
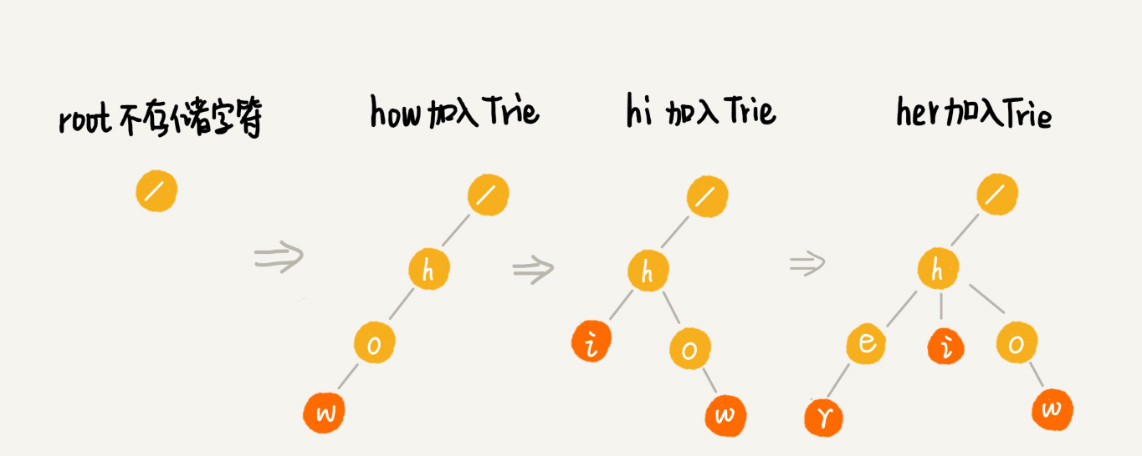
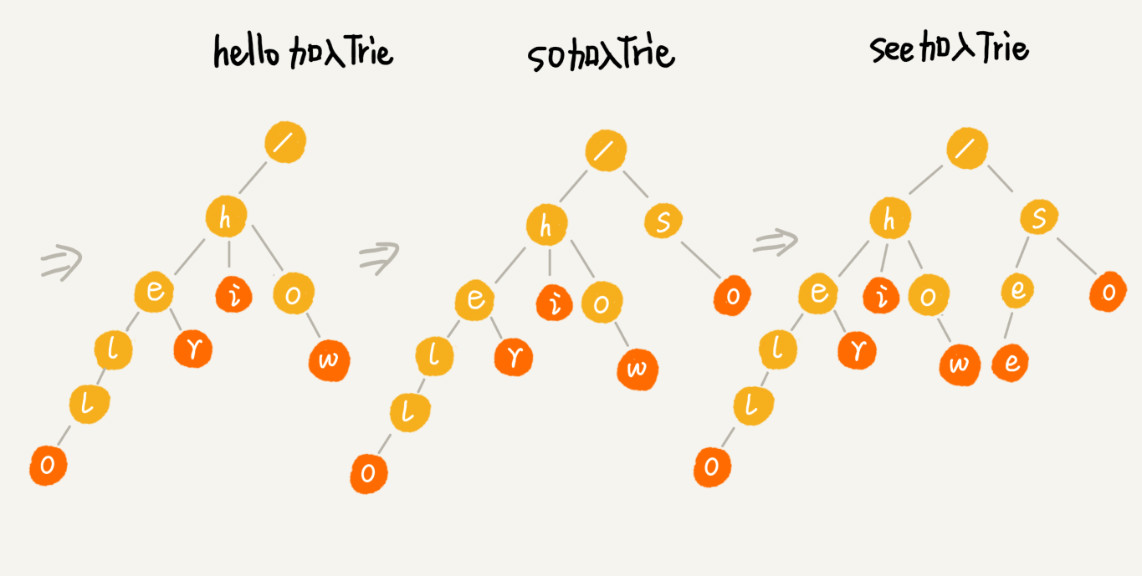
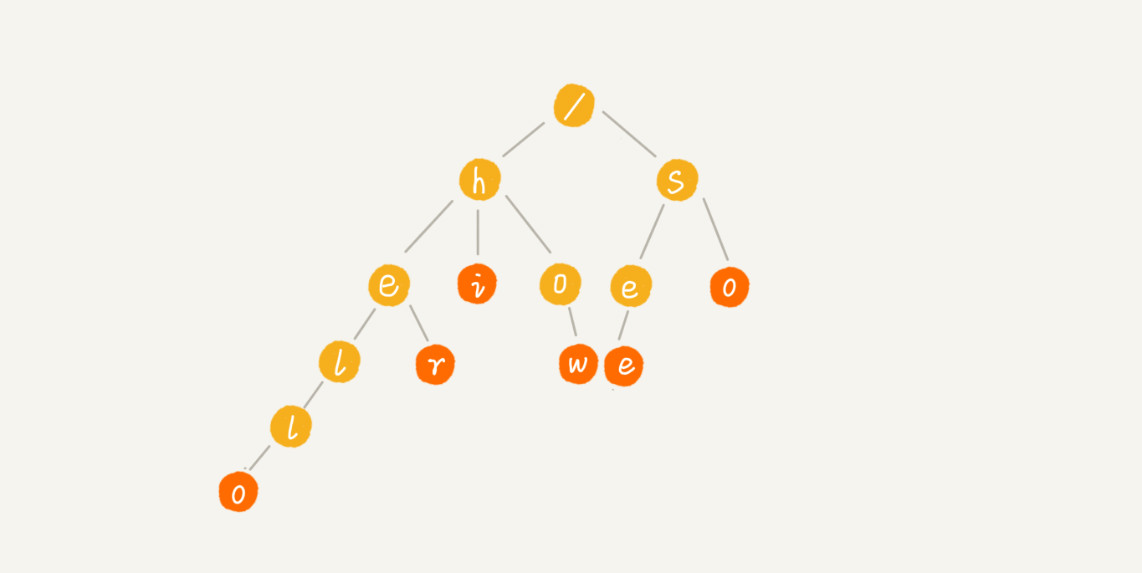
当在 Trie 树中查找一个字符串的时候,比如查找字符串“her”,那我们将要查找的字符串分割成单个的字符 h,e,r,然后从 Trie 树的根节点开始匹配。
存储数据结构
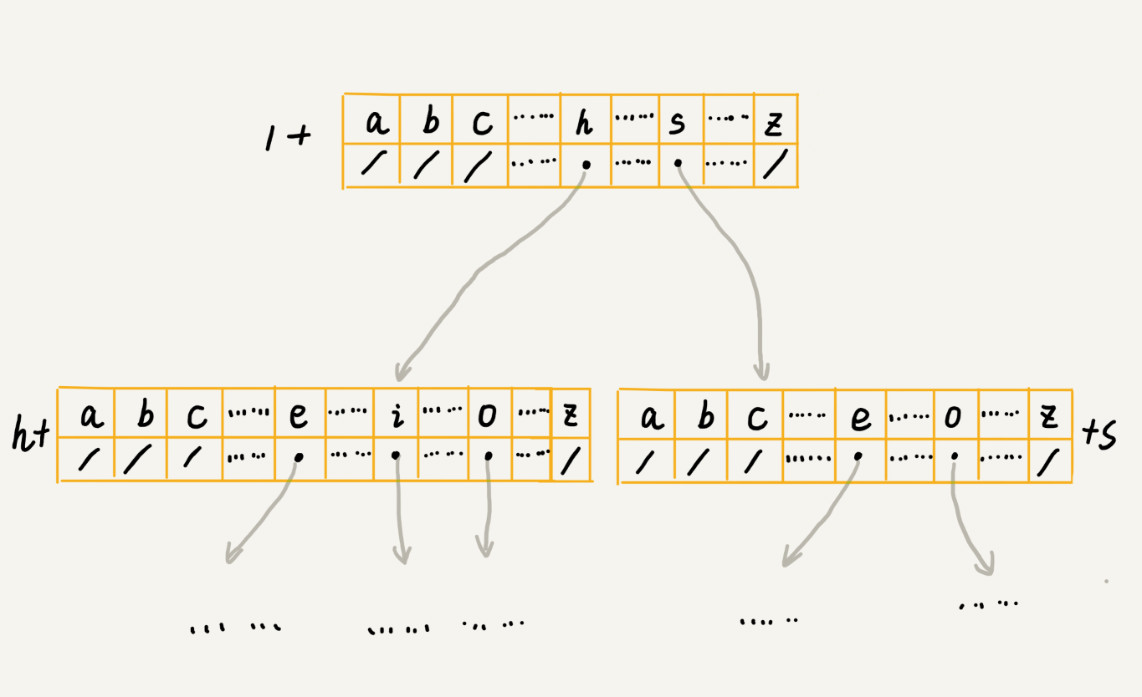
|
假设我们的字符串中只有从 a 到 z 这 26 个小写字母,我们在数组中下标为 0 的位置,存储指向子节点 a 的指针,下标为 1 的位置存储指向子节点 b 的指针,以此类推,下标为 25 的位置,存储的是指向的子节点 z 的指针。如果某个字符的子节点不存在,我们就在对应的下标的位置存储 null。 当我们在 Trie 树中查找字符串的时候,我们就可以通过字符的 ASCII 码减去“a”的 ASCII 码,迅速找到匹配的子节点的指针。比如,d 的 ASCII 码减去 a 的 ASCII 码就是 3,那子节点 d 的指针就存储在数组中下标为 3 的位置中。
|