redis高可用
redis高可用
- 主从复制
- sentinel
- cluster
主从复制
主要目的是读写分离,负载均衡。
slaveof 命令, 主服务可以进行读写操作,写操作导致变化是同步给从数据库。slave一般是只读,接受主数据同步过来的数据。
实现原理步骤:
- 从服务器向主服务器发送SYNC命令
- 主服务器收到SYNC命令后,执行BGSAVE命令,在后台生成RDB文件,使用缓冲区记录从现在开始执行的所有的写命令。
- 当主服务器的BGSAVE命令执行完毕后,主服务器后将BGSAVE命令生成的RDB文件发送给从服务器,从服务器接收并载入这个RDB文件,将自己的数据库状态更新至主服务器执行BGSAVE命令时的数据库状态。
- 主服务器将记录在缓冲区里面的所有写命令发送给从服务器,从服务器执行这些写命令,将自己的数据库状态更新至主服务器数据库当前所处的状态。

主从连接时先全量同步,全同步完成后进行增量复制。
replication是非阻塞方式完成的,同步期间仍可以处理请求。
一个master可以有多个slave replica, 如果单个master多个slave,同步数据导致较大负担,可考虑master-slave链式结构
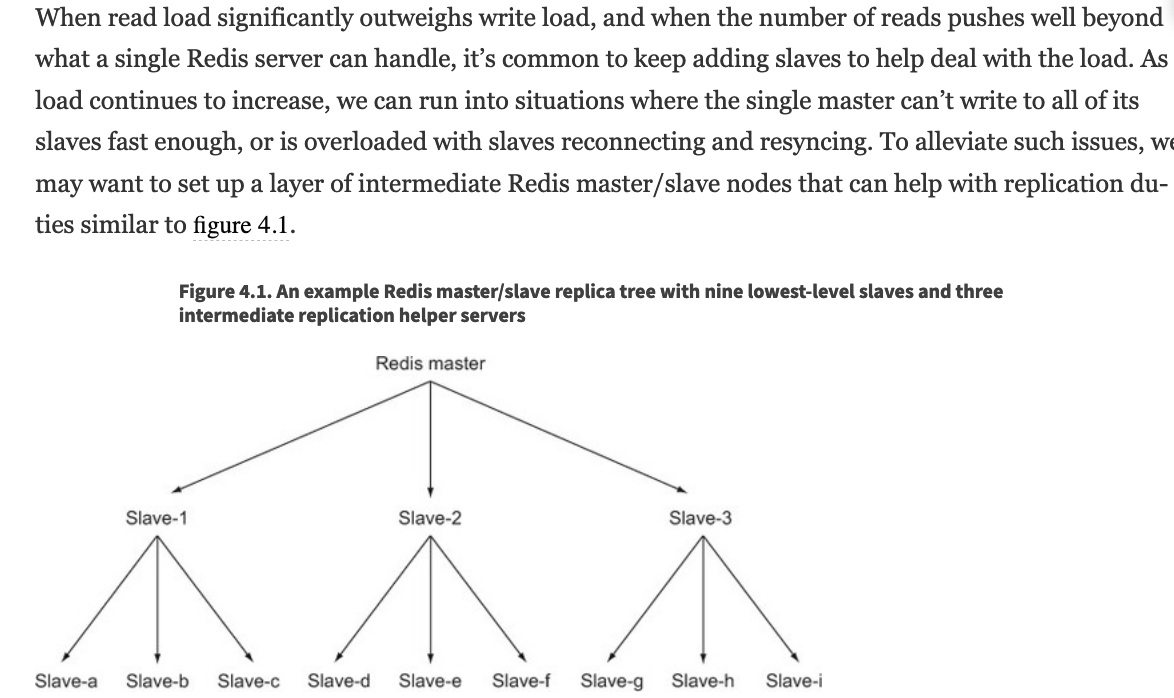
问题:当master down, 需手动将slave 提升为master。自动的话需要sentinel; master宕机后,如果数据没有同步到slave,slave被手动提升为master后可能数据有丢失。
Sentinel
sentinel主要是解决高可用问题,监控服务节点,如果发现master宕机自动将slave切换为master。
sentinel 的作用:
- 监控: 定期监控mater和replica的健康
- 通知: 通过API
- 自动的failover: 如果master认为不可用,sentinel可以启动failover是得replica变成master
- 配置管理:client可以连接sentinel, sentinel返回redis server信息
通常会多个sentinel:
- 多个sentinel同意master 不可用,防止误判
- sentinel可以正常工作,即使部分sentine不可用
当有多个Sentinel,在进行监视和转移主从服务器时,Sentinel之间会自己首先进行选举,选出Sentinel的leader来进行执行任务。
1. 主观下线Subjectively Down condition (SDOWN):一个哨兵节点判定主节点down掉是主观下线。sentinel没有收到正确的恢复在_is-master-down-after-milliseconds_时间内,认为是SDOWN
2.客观下线Objectively Down condition (ODOWN) :只有半数哨兵节点都主观判定主节点down掉,此时多个哨兵节点交换主观判定结果,才会判定主节点客观下线。
3.原理:基本上哪个哨兵节点最先判断出这个主节点客观下线,就会在各个哨兵节点中发起投票机制Raft算法(选举算法),最终被投为领导者的哨兵节点完成主从自动化切换的过程。
How it work:
每个Sentinel(哨兵)进程以每秒钟一次的频率向整个集群中的 Master 主服务器,Slave 从服务器以及其他Sentinel(哨兵)进程发送一个 PING 命令。
如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel(哨兵)进程标记为主观下线(SDOWN)
如果一个 Master 主服务器被标记为主观下线(SDOWN),则正在监视这个 Master 主服务器的所有 Sentinel(哨兵)进程要以每秒一次的频率确认 Master 主服务器的确进入了主观下线状态
当有足够数量的 Sentinel(哨兵)进程(大于等于配置文件指定的值)在指定的时间范围内确认 Master 主服务器进入了主观下线状态(SDOWN), 则 Master 主服务器会被标记为客观下线(ODOWN)
一般情况下, 每个 Sentinel(哨兵)进程会以每 10 秒一次的频率向集群中的所有 Master 主服务器、Slave 从服务器发送 INFO 命令。
当 Master 主服务器被 Sentinel(哨兵)进程标记为客观下线(ODOWN)时,Sentinel(哨兵)进程向下线的 Master 主服务器的所有 Slave 从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
若没有足够数量的 Sentinel(哨兵)进程同意 Master主服务器下线, Master 主服务器的客观下线状态就会被移除。若 Master 主服务器重新向 Sentinel(哨兵)进程发送 PING 命令返回有效回复,Master主服务器的主观下线状态就会被移除。
Sentinel配置
sentinel monitor <master-group-name> <ip> <port> <quorum>
quorum- master被确定为不可用需要多少个Sentinel同意。但是该配置只用于决定是否节点不可用,执行failover时Sentinel会内部选举出leader 来执行failover(需要大多数Sentinel进程同意)
例子:
如果5个Sentinel,quorum配置为2, 当2个Sentinel发现节点不可用,可以启动failover;如果同时有3个Sentinel可以互相连接(达到多数标准),failover可以执行。
failover 必须大多数Sentinel可彼此连通才可能会发生
配置项:
down-after-milliseconds mymaster 5000 (sentinel ping命令多久没收到reply会认为node不可用)
failover-timeout mymaster 180000 (failover 的timeout)
sentinel的基本部署
1-2-3 (1个master,2个replica,3个sentinel)
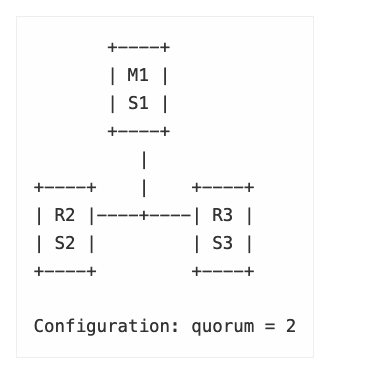
如果M1 fail, S2和S3可以决定节点不可用并可以执行failover。
问题是写丢失:如果有client连接M1, M1不可用,client继续写导致丢失。当master节点上线后,会变成新的master的replica,该节点的数据会被清除并与新的master sync。
cluster
解决单机Redis容量有限的问题,将数据按一定的规则分配到多台机器。
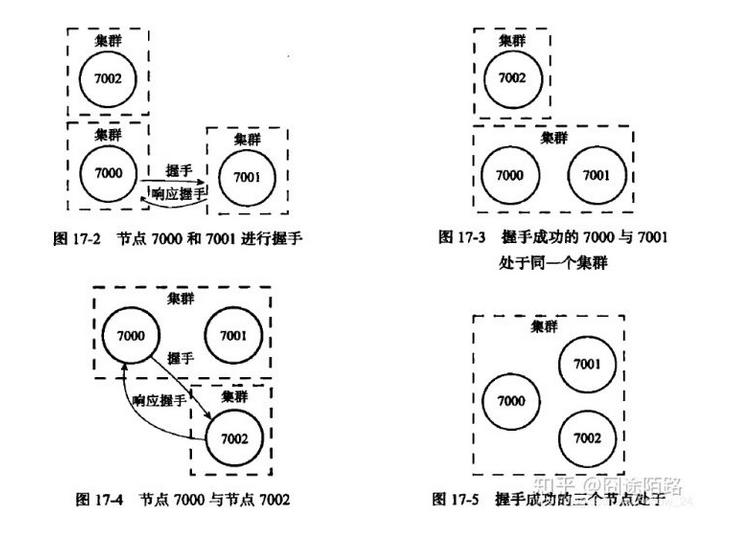
各个节点互相连通,客户端可以和任何节点相连。
数据分片
没有使用一致hash,使用hash slot
Redis 集群有16384 个哈希槽,每个 key 通过 CRC16 校验后对 16384 取模来决定放置哪个槽。
比如当前集群有3个节点:
- 节点 A 包含 0 到 5460 号哈希槽
- 节点 B 包含 5461 到 10922 号哈希槽
- 节点 C 包含 10923 到 16383 号哈希槽
https://zhuanlan.zhihu.com/p/62947738