MongoDB replicaSet
MongoDB replicaSet
Replica Set
https://docs.mongodb.com/manual/core/replica-set-architectures/
replication has been particularly important for MongoDB’s durability.
- redundancy - replicated node he primary node 保持一致 (async)
- failover - 保证HA, primary down,elect new primary (存在不可用的time window during election)
- maintain - 例如building index 是expensive的操作,可以先在secondary build index, 在切换primary 和 secondary, 然后在新的secondary build index。。。
- balance read - 参考 read preference , 由于replication是async,如果read 到slave 可能会读取到stale data,因此如果需要强一致性,则到secondary read 不适用。
Replication is the process of synchronizing data across multiple servers. Replication provides redundancy and increases data availability with multiple copies of data on different database servers, replication protects a database from the loss of a single server. Replication also allows you to recover from hardware failure and service interruptions. With additional copies of the data, you can dedicate one to disaster recovery, reporting, or backup.
In a replica set one node is primary node that receives all write operations and all other nodes acts as secondaries. Replica set can have only one primary node.After each successive writes to the primary node, MongoDB will replicate the same data to all the secondary nodes present in the replica set.
最小配置
三个node
Primary
primary 是唯一接受write的节点
Secondary:
maintain copy of primary node, 通过OPlog
Arbiter: 不存储数据,vote, break the tie
https://docs.mongodb.com/manual/core/replica-set-architecture-three-members/
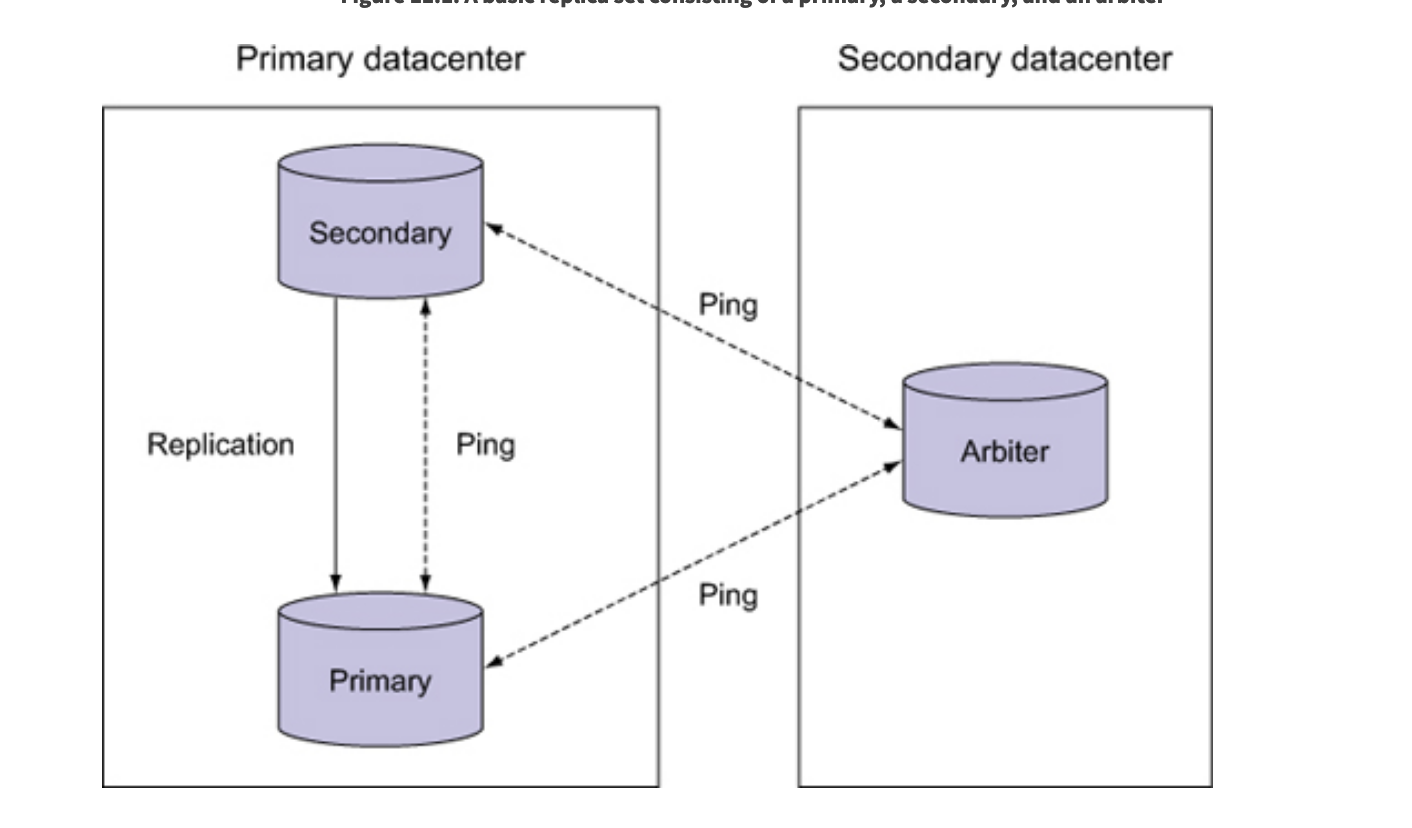
核心
- oplog
- heartbeat
The oplog enables the replication of data, and the heartbeat monitors health and triggers failover.
oplog
check 5.oplog
heartbeat
replica member 发送heartbeat every 2 seconds,如果10秒内没有reply 认为 inaccessible
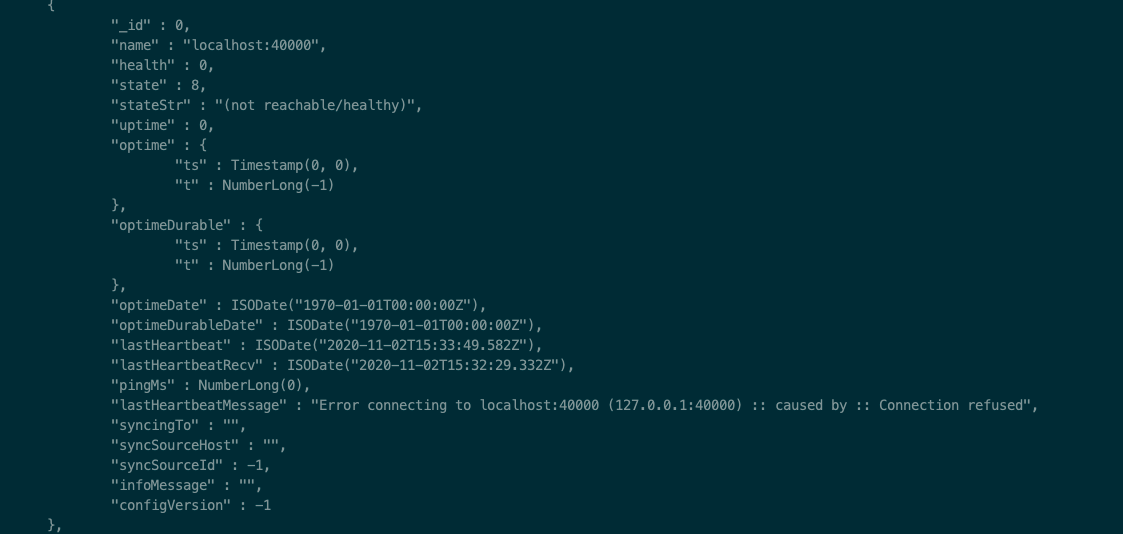
rs.status() 可以看到heartbeat 信息
{ |
Data Sync
initial sync to populate new members with the full data set, and replication to apply ongoing changes to the entire data set
- Clone all databases except the local database from source
- Applies all changes to the data set,using the oplog from the source
Election
影响election的因素
- priority , priority高的node 更有可能再election 中成为primary
members[n].votes, 不参与vote的node 必须priority也设置为0, 默认node vote num 为1,不建议更改
FailOver
通常driver 连mongo 是配置多个replica instance.
虽然failover 是自动发生,但是election 过程会导致短暂的cluster 对写不可用(CP DB)。 driver 会报出相应failover的log,通常driver 会自动重连
First, the primary fails or a new election takes place. Subsequent requests will reveal that the socket connection has been broken, and the driver will then raise a connection exception and close any open sockets to the database.
相关 MongoCap.md
1. 为什么建议奇数个节点?
primary down,需要elect new primary, voting 需要majority of voting members。
假定有三个node A, B and C
如果A 宕机,B和C(two out of three)仍然满足majority的要求可以正常完成election. B和C谁成为Primary 取决于b和c的priority,如果相同的话, most up-to-date oplog wins。假定是B变为新的primary,如果A 恢复正常,不会有新的election,C和A变成secondary。
如果有两个node 宕机,整个集群无法接受写请求直到至少一个server恢复。
假定有四个node,如果一个node宕机,正常election;如果两个node 宕机,2/4无法构成majority,仍然无法响应write,cluster变成只读mode。
推荐奇数node:因为即使4个node(比3个node多一个),对于失去两个node 同样无法执行election来选举新的primary。
The key point is having no redundancy gain out of an even set up.

2. 关于secondary
三类特殊的secondary
- Prevent it from becoming a primary in an election, which allows it to reside in a secondary data center or to serve as a cold standby. See Priority 0 Replica Set Members.
- Prevent applications from reading from it, which allows it to run applications that require separation from normal traffic. See Hidden Replica Set Members.
- Keep a running “historical” snapshot for use in recovery from certain errors, such as unintentionally deleted databases. See Delayed Replica Set Members.
配置
arbiterOnly
Indicating whether this member is an arbiter.
priority
0 to 1000 that helps to determine the relative eligibility that this node will be elected primary.
使用场景: 集群内部有些机器性能更为强大,因此可以通过priority设置来讲此node 设置为preferred primary当election 发生时。
hidden
{ |
A hidden member maintains a copy of the primary’s data set but is invisible to client applications.
可以和buildIndex结合使用,但是必须指定slaveDelay
hidden member 仍然可以vote, read 不会到hidden。
buildIndex
默认是true,设置false的场景:node不会做primary(priority0),node只是做backup。
slaveDelay
The number of seconds that a given secondary should lag behind the primary
使用场景: node不会做primary,priority设置为0. 例如指定30分钟,因此数据会有30分钟的延迟,如果误操作了db有30分钟的delay“脏”数据不会进到slave。
3. arbiter
An arbiter does not store a copy of the data and requires fewer resources. As a result, you may run an arbiter on an application server or other shared process. With no copy of the data, it may be possible to place an arbiter into environments that you would not place other members of the replica set.
Arbiters are lightweight mongod servers that participate in the election of a primary but don’t replicate any of the data.
4. oplog
The oplog is a capped collection that lives in a database called local on every replicating node and records all changes to the data. Foreach write, entry with enough information to reproduce the write is automatically added to the primary’s oplog.
测试数据
myapp:PRIMARY> use bookstore |
local db中存在一个collection -oplog.rs
myapp:PRIMARY> db.oplog.rs.find({op: "i"})
|
key fields:
- First arg,the timestamp includes two numbers; the first representing the seconds since epoch and the second representing a counter value—1 in this case. T
- op field specifies the opcode.
- ns - namespace (db + collection)
- lowercase letter o, which for insert operations contains a copy of the inserted document.
Oplog Size
By default, the mongod process creates an oplog based on the maximum amount of space available. For 64-bit systems, the oplog is typically 5% of available disk space.
因为oplog 是一个有大小上限的collection,这就意味着oplog只能存储固定大小的数据。通常默认的size 是足够的,但对于high write volume的场景需要结合可承受的secondary 宕机时间来设定oplog size, 防止出现secondary 落后太远没法catch up oplog
5. WriteConcern
replica 节点(除了arbiter) 需要ack write
默认是1,也就是write 只有顺利到达primary server 才会认为write 成功, 可以根据场景设置,例如如果要确保write 需要被replicate 到至少一个server,可以设置w为2。还有一个参数wtimeout, 指定replicate 数据的最大timeout时间。
每次写的时候可以指定w和wtimeout参数
Eg
db.products.insert( |
目的: 防止 replica set rollback. - w: majority + j:true (write to journal).
A rollback reverts write operations on a former primary when the member rejoins its replica set after a failover.
A rollback does not occur if the write operations replicate to another member of the replica set before the primary steps down and if that member remains available and accessible to a majority of the replica set.
Keep in mind that using write concerns with values of w greater than 1 will introduce extra latency.If you’re running with journaling, then a write concern with w equal to 1 should be fine for most applications.
6. ReadPreference
默认read 会到primary, 可以通过readpreference customize。
- *primary* : 默认
- *primaryPreferred* : 除非primary 由于某些原因not avaibale才会到secondary
- *secondary* : alwasy secondary, 如果secondary 不可用,exception is thrown out
- *secondaryPreferred* : 首先考虑secondary,secondary 不可用才到primary
- *nearest* : The driver reads from a member whose network latency falls within the acceptable latency window. Reads in the
nearestmode do not consider whether a member is a primary or secondary when routing read operations: primaries and secondaries are treated equivalently.
Notes
Remember, the primary read preference is the only one where reads are guaranteed to be consistent. Writing is always done first on the primary. All read preference modes except primarymay return stale data because secondaries replicate operations from the primary in an asynchronous process. Ensure that your application can tolerate stale data if you choose to use a non-primarymode.
另外如果有high write load, 由于secondary 需要keep up with primary, read direct 到secondary 反而可能影响replication。
## Appendix
Settingup ReplicaSet
创建db folder
|
启动mongo node
|
连接到一个非arbiter的node, 设置replica set
mongo --port 40000 |
查看rs
db.isMaster()
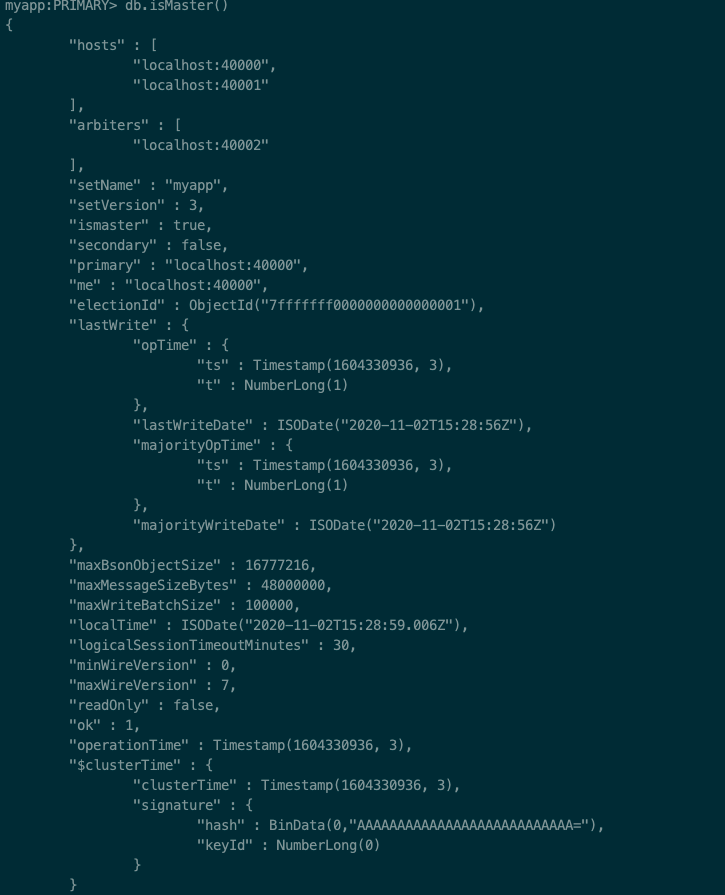
rs.status() 查看详细信息
测试fail over
$ mongo --port 40000 |