MongoDB Indexing
MongoDB Indexing
index : 提升query 性能,但是会有额外的cost 因为对于写操作需要维护index。 因此对于read-intensive 的应用,index 会有很大帮助。
Data structure
B-Tree: search, sequential access, inserts, and deletes to be performed in logarithmic time.
Another interesting property of a B-tree is that it is self-balancing - 高度小
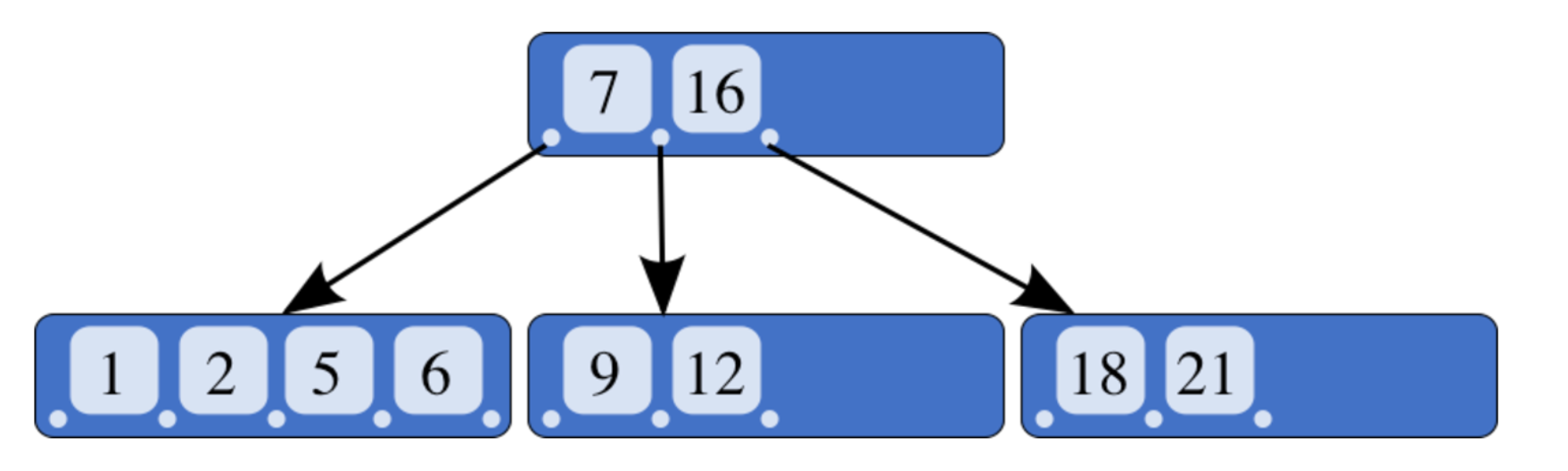
Single field Index
最常用的index 类型
db.books.createIndex( { price: 1 } ) ascending
db.books.createIndex( { price: -1 } ) descending
该索引使用: exact match or range query
Compound Index
db.books.createIndex({"name": 1, "isbn": 1})
Sorting in compound index
compound index 多个字段 的 ascending 和 descending 应当一致
prefix indexing
顺序重要- 左匹配
db.books.createIndex({"name": 1, "isbn": 1}) 如果按照name 或者 name+isbn 查询都可以从index 获益, 但是如果查询isdn 则无法使用该idnex。
常用的index 种类
unique index
类似于RMDBs的unique , 防止index filed 存在duplicate value.
db.users.createIndex({username: 1}, {unique: true}) |
TTL
Time to live indexes are used to automatically delete documents after an expiration time.
createIndex( { "created_at_date": 1 }, { expireAfterSeconds: 86400 } )
The created_at_date field values have to be either a date or an array of dates (the earliest one will be used)
sparse index
Indexes are dense by default.
使用场景: 如果某个field不是在所有doc中都存在。
multikey index
对于内容为数组的filed
{ |
hashed index
index 字段首先通过hash function做hash
db.recipes.createIndex({recipe_name: 'hashed'}) |
hashed index is ideal for equality matches but cannot work with range queries.
Hashed indexes are used internally by MongoDB for hashed-based sharding : the entries in a hashed index are evenly distributed.
Eg: If your shard index is based on an increasing value, such as a MongoDB OIDs,[7] then new documents created will only be inserted to a single shard—unless the index is hashed.
跟shariding 有关,防止doc 都聚集在同一个shard ,对于heavy write 可以确保doc 均匀分布在不同sharding
Index management
best scenario: index 在空库添加,这样index 可以incremental build。
exception : 对于数据迁移或者是对已经存在数据的db或collection 创建index, index build 是比较expensive的操作(sorting + index creation ),对于大数据量的index build 可能会花很久 而且index build 很难被kill 掉。
check index: getIndexes() or getIndexSpecs()
eg paymentdb. session
db.session.createIndex({ created: 1 }, { expireAfterSeconds: 1800 }); |
db.lock.createIndex( { "expireAt": 1 }, { expireAfterSeconds: 3600 } ) |
options:
- background index
- offline index
background index
createIndex( { name: 1 }, { background: true } )
index 可以通过mongoshell 或者driver 来管理, 默认的index build 是foreground, 会blocking 其他操作
Although the index build will still take a write lock, the job will yield to allow other readers and writers to access the database. 更好的做法选在 wirite load 比较小的时候 去做 backgroud index build
offline build index
- Stop one secondary from the replica set
- Restart it as a standalone server in a different port
- Build the index from the shell as a standalone index
- Restart the secondary in the replica set
- Allow the secondary to catch up with the primary
query optiomization
主要是先定位slow queries,然后查看原因,最后是action
Check Appendix for sample data
1. 定位slow query
Using the db.setProfilingLevel(2) most verbose level; it directs the profiler to log every read and write.
db.setProfilingLevel(1, 50), 记录query时间超过特定阈值(50ms)
可以从 system.profile (capped collection) 查找
db.system.profile.find({millis: {$gt: 150}}) |
Key fields:
- docsExamined: The number of documents in the collection that MongoDB scanned in order to carry out the operation.
- nreturned: The number of documents returned by the operation.
Ref: https://docs.mongodb.com/manual/reference/database-profiler/
2. examing slow queries
db.values.find({"stock_symbol": "GOOG"}).sort({date: -1}).limit(1).explain("executionStats") |
最主要的就是returned 和 examined 应该是相近的数字。
3. actions
最简单的场景是添加index,或者调整index,调整data model etc...
db.values.createIndex({close: 1}) |
> db.values.getIndexes();
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "stocks.values"
},
{
"v" : 2,
"key" : {
"close" : 1
},
"name" : "close_1",
"ns" : "stocks.values"
}
]
> db.values.getIndexes(); |
query optimizer
Query optimizer is the piece of software that determines which index, if any, will most efficiently serve a given query.
Optimizer chooses the index that requires scanning the least number of index entries.
When the query is first run, the optimizer creates a query plan for each index that might efficiently satisfy the query. The optimizer then runs each plan in parallel. Usually, the plan that finishes with the lowest value for nscanned is declared the winner; but in rare occasions, the optimizer may select the full collection scan as the winning plan for a given query. The optimizer then halts any long-running plans and saves the winner for future use.
Appendix
启动mongo, Reset and restart MongoDB
rm -rf ~/Env/mongodb-osx-x86_64-4.0.5/data/db/ && mkdir -p ~/Env/mongodb-osx-x86_64-4.0.5/data/db && mongod --dbpath ~/Env/mongodb-osx-x86_64-4.0.5/data/db |
mongorestore
mongorestore -d stocks stocks
Index
db.values.getIndexes(); |
Sample
> db.values.count(); |