Kubernetes 系列2
Kubernetes 系列2
Pod
In real-world use cases, you want your deployments to stay up and running automatically and remain healthy without any manual intervention. To do this,you almost never create pods directly
ReplicationController/ReplicaSet or Deployment
1. Replica
- Reliability
- Scaling
- load balance
Ensures pods are always kept running and the actual number of pods of a “type” always matches the desired number.
Label
https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/
Labels are the mechanism you use to organize Kubernetes objects.
kubectl get pods --show-labels |
ReplicaSet
- A label selector, which determines what pods are in the replicaset scope
- A replica count, which specifies the desired number of pods that should be running
- A pod template, which is used when creating new pod replicas
springboot-rs.yaml
apiVersion: apps/v1 |
kubectl create -f springboot-rs.yaml |
Scaling the number of pods up or down is as easy as changing the value of the replicas field in the replicaSet resource. Horizontally scaling pods in Kubernetes: You’re not telling Kubernetes what or how to do it. You’re just specifying the desired state.
- CMD:
kubectl scale rc ?? --replicas=10 - Dashboard do the scaling (up or down)
https://kubernetes.io/docs/concepts/workloads/controllers/replicationcontroller/
https://kubernetes.io/docs/concepts/workloads/controllers/replicaset/
Notes Replica Set is the next generation of Replication Controller. A Deployment that configures a ReplicaSet is now the recommended way to set up replication.
2. Service
In the case of microservices, pods will usually respond to HTTP requests coming either from other pods inside the cluster or from clients outside the cluster.
Why can we use the IP of pod for discovery?
- Pods are ephemeral—They may come and go at any time, whether it’s because a pod is removed from a node to make room for other pods, because someone scaled down the number of pods, or because a cluster node has failed.
- Kubernetes assigns an IP address to a pod after the pod has been scheduled to a node and before it’s started—Clients thus can’t know the IP address of the server pod up front.
- Horizontal scaling means multiple pods may provide the same service—Each of those pods has its own IP address. Clients shouldn’t care how many pods are backing the service and what their IPs are. They shouldn’t have to keep a list of all the individual IPs of pods. Instead, all those pods should be accessible through a single IP address.
A Kubernetes Service is a resource you create to make a single, constant point of entry to a group of pods providing the same service. Connections to the service are load-balanced across all the backing pods.
2.1 Interal Cluster
https://kubernetes.io/docs/concepts/services-networking/service/
Create Svc
kubectl create -f springboot-svc.yaml |
Test - Deploy a curl POD which is a pod inside same cluster which can use curl to access services within cluster
curlpod.yaml
apiVersion: v1 |
kubectl apply -f curlpod.yaml |
Environmnt Variable
When a pod is started, Kubernetes initializes a set of environment variables pointing to each service that exists at that moment.
printenv | grep SERVICE
curl {clusterIP}:{port}/demo/ping
DNS
kube-dns under kube-system namespace
Any DNS query performed by a process running in a pod will be handled by Kubernetes’ own DNS server, which knows all the services running in your system
curl http://springboot-svc.default.svc.cluster.local/demo/ping curl http://springboot-svc/demo/ping
2.2 External Acesss
NodePort
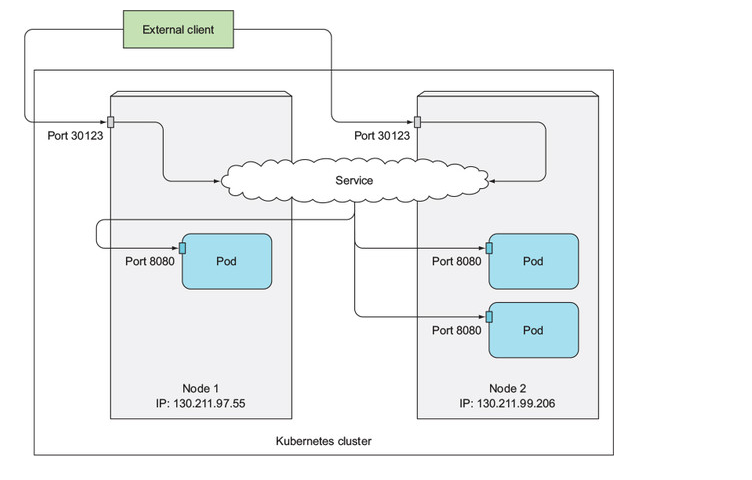
|
Loadbalancer
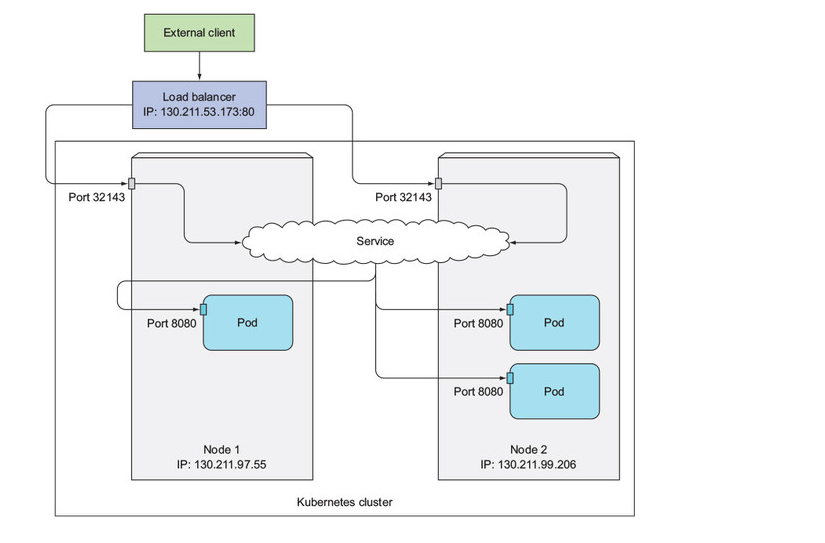
Ingress
Ingress exposes HTTP and HTTPS routes from outside the cluster to services within the cluste
One important reason is that each LoadBalancer service requires its own load balancer with its own public IP address, whereas an Ingress only requires one, even when providing access to dozens of services.
https://kubernetes.io/docs/concepts/services-networking/ingress/
3. Volume
volume is available to all containers in the pod, but it must be mounted in each container that needs to access it. In each container, you can mount the volume in any location of its filesystem.
https://kubernetes.io/docs/concepts/storage/volumes/
PersistentVolumes and PersistentVolumeClaims (DECOUPLING THE UNDERLYING STORAGE TECHNOLOGY)
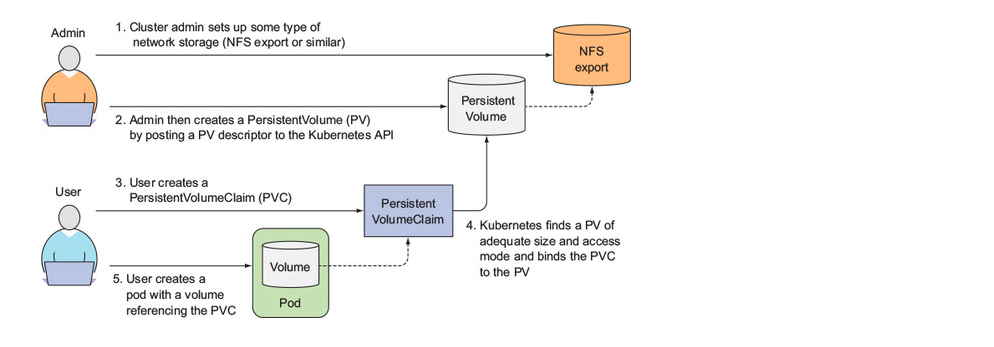
4. ConfigMap And Secret
Passing configuration options to an application that’s widely popular in containerized applications is through environment variables.
Using configuration files inside Docker containers is a bit tricky, because you’d have to bake the config file into the container image itself or mount a volume containing the file into the container. Obviously, baking files into the image is similar to hardcoding configuration into the source code of the application, because it requires you to rebuild the image every time you want to change the config. Plus, everyone with access to the image can see the config, including any information that should be kept secret, such as credentials or encryption keys.
ConfigMap vs Secret Use a ConfigMap to store non-sensitive, plain configuration data. Use a Secret to store any data that is sensitive in nature and needs to be kept under key.
4.1 ConfigMap
credentials and private encryption keys, which need to be kept secure.
ConfigMap is a map containing key/value pairs with the values ranging from short literals to full config files.
The contents of the map are instead passed to containers as either environment variables or as files in a volume
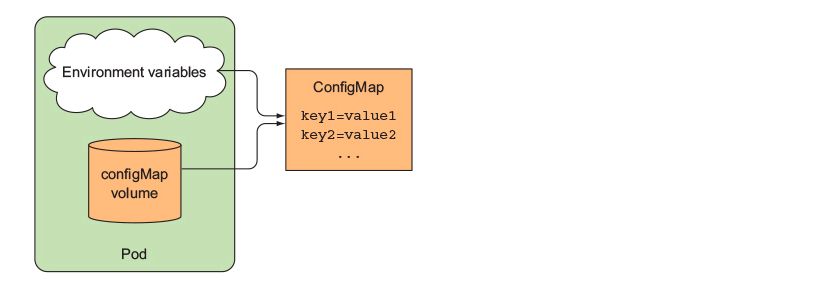
Srping boot PRING_PROFILES_ACTIVE
apiVersion: v1 |
|
kubectl apply -f springboot-demo-configmap.yaml |
4.2 Secret
echo "CREDENTIAL=passw0rd" > ./bootstrap.properties |
kubectl apply -f springboot-demo-secret.yaml |
apiVersion: v1 |
Ref: https://kubernetes.io/docs/concepts/configuration/secret/#using-secrets-as-files-from-a-pod